擒数网 (随信APP) | 挑战Sora!Adobe发布人工智能视频工具,将视频处理变得轻而易举。

擒数网 (随信APP) | 挑战Sora!Adobe发布人工智能视频工具,将视频处理变得轻而易举。
【微信/公众号/视频号/抖音/小红书/快手/bilibili/微博/知乎/今日头条同步报道】
最近AI视频领域异常热闹,Adobe也刚刚加入了这场混战。
在今年的Adobe Max大会上,Adobe正式推出了自己的AI视频模型——Firefly Video Model,进军生成式人工智能领域。

Adobe的首席产品营销经理Meagan Keane表示,Firefly Video Model的推出旨在简化加速视频创作,并且增加视频的故事讲述能力。概括来讲,这个模型包含三个有趣且实用的功能:
- Generative Extend(生成拓展)
- Text-to-Video(文生视频)
- Image-to-Video(图生视频)
其中,Generative Extend已经被集成至Adobe所开发的专业视频编辑软件Premiere Pro当中;Text-to-Video和Image-to-Video则刚刚在Firefly Web app中推出beta版本。
顾名思义,如果你拍摄的视频片段太短或缺失某些部分,Generative Extend可以帮你在视频片段的开头或结尾进行「生成式扩展」。
也就是说,假如所需的镜头不可用,或者某个镜头的剪辑时机过早或过晚,剪辑师只需要拖动该视频片段的开头或结尾,Generative Extend就可以自动填充生成式内容,以保持视频的连贯、平滑。
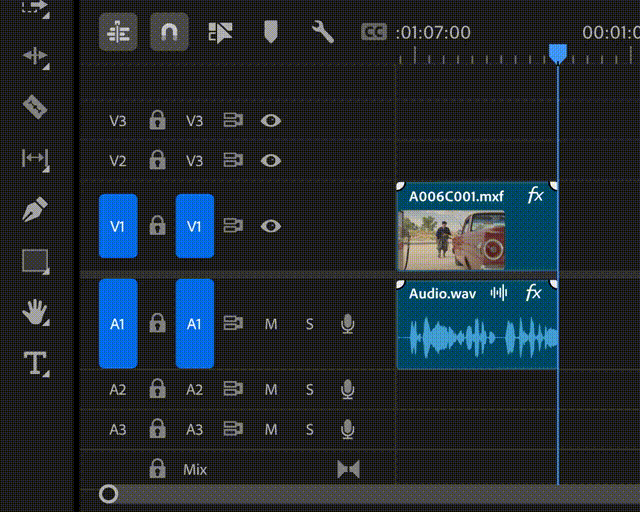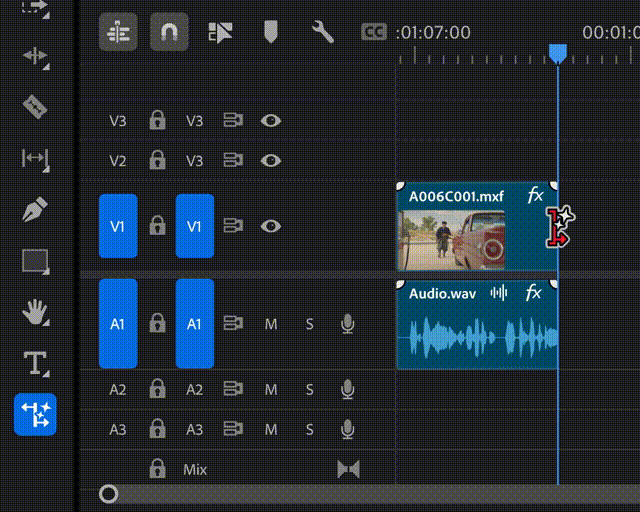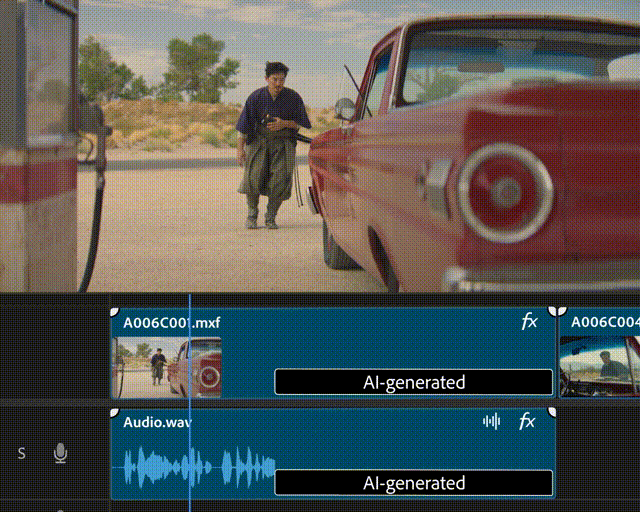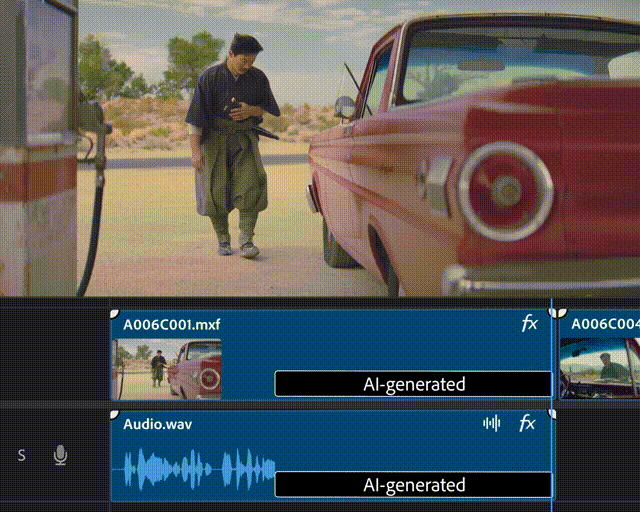
▲Generative Extend的生成式视频扩展功能演示(图片来源:Adobe)
这意味着如果视频创作者在拍摄过程中得到了一个「废镜头」,他可能不再需要回到原场地重新拍摄,而是利用Generative Extend直接对原片段进行扩展和修复。
一定程度上讲,这确实有助于提高视频创作效率——当然,是在Generative Extend所延伸的片段质量过硬的情况下。
遗憾的是,该功能目前的最大分辨率限制为1080p,且片段最长只能扩展两秒钟。
因此Generative Extend只适合对视频片段进行微小的调整,即它只能帮助用户修复某些细节,却不能代替创作者本身,进行大篇幅的创作。
Generative Extend还可以帮助用户拍摄过程中进行调整,纠正在拍摄过程中视线偏移或其他意外产生的移动。

除了视频之外,Generative Extend还可以用于音频的平滑编辑。它可以将视频中的环境背景音效扩展长达十秒钟时间,但无法对对话或音乐进行拓展。
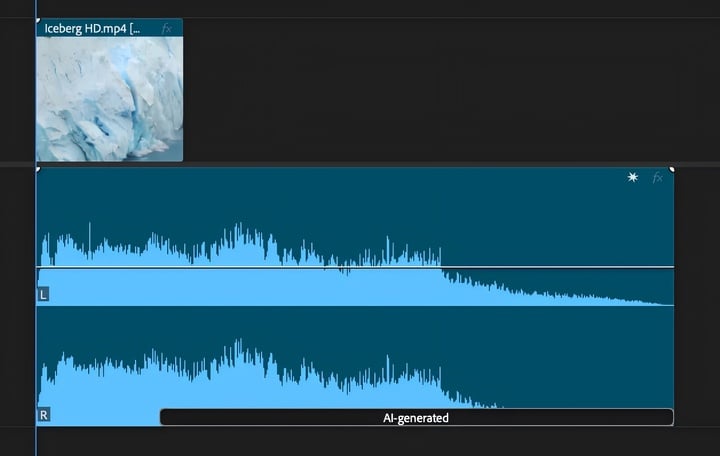
▲Generative Extend的音频扩展功能示意(图片来源:Adobe)
如果你想在视频创作过程中省点力气,你可以使用Text-to-Video功能直接生成。同它的「老前辈」Runway和OpenAI的Sora一样,用户只需要输入他们想要生成的视频的文本描述,它就可以模拟「真实电影」、「3D动画」和「定格动画」等各种风格生成相应的视频片段。
以下是一些使用Text-to-Video功能生成视频片段,感受一下:

▲提示文本:电影无人机飞越广阔的红色火星景观,它从我们脚下飞驰而过,当太阳升起时,地平线是红色的。在镜头的结尾,太阳从地平线上升起。(图片来源:Adobe)

▲提示文本:电影特写和夜晚街道中央一位老人的肖像细节。灯光气氛沉闷,充满戏剧性。颜色等级为蓝色阴影和橙色高光。这个男人有极其逼真的细节皮肤纹理和明显的毛孔。动作微妙而柔和。相机不动。胶片颗粒。老式变形镜头。(图片来源:Adobe)

▲提示文本:在墨西哥一个美丽、柔和的天井内拍摄的视角。水清澈湛蓝,在傍晚的阳光下闪闪发光。颜色是温暖和神奇的魔幻风格。高品质,电影感。(图片来源:Adobe)
除了逼真的,电影般的视觉影像,Text-to-Video还支持生成一些「抽象」的画面。例如,它可以被用来生成包括火焰、水、漏光和烟雾等元素的视频,并覆盖叠加到现有的视频上,来增加现有内容的视觉深度和趣味性。
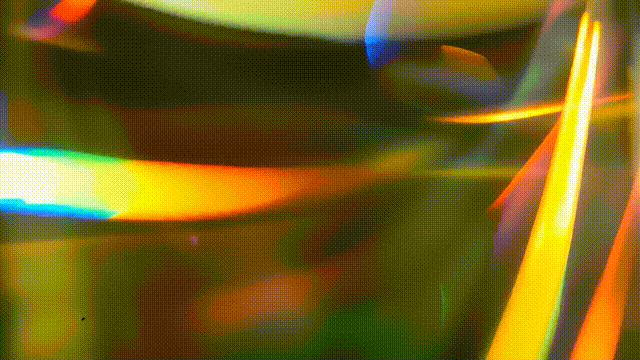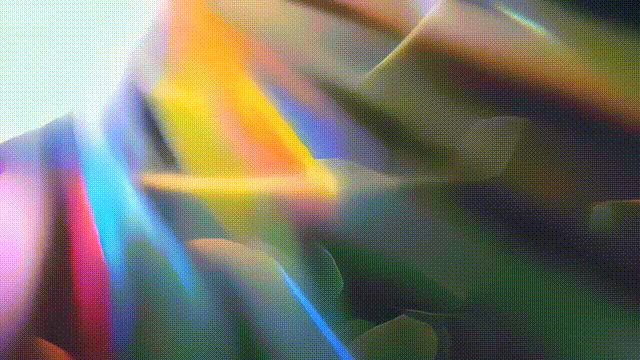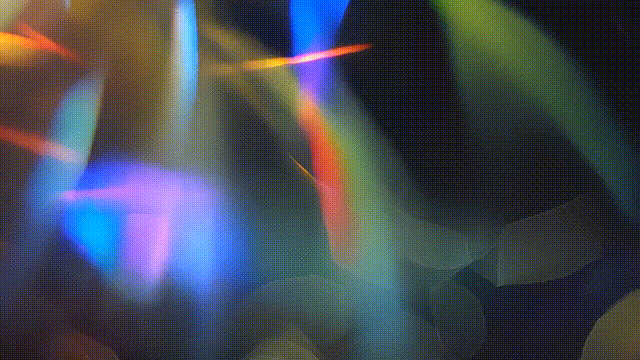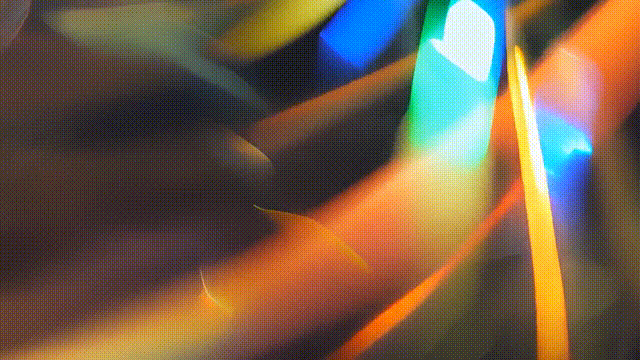
▲提示文本:黑色背景上的电影漏光,有机质感,逼真。(图片来源:Adobe)

▲上述视频与现有视频合成后生成的视频片段(图片来源:Adobe)
值得一提的是,用Text-to-Video生成的视频片段还可以使用一系列「相机控制」进行进一步细化处理,这些控制能够模拟真实的相机角度、运动和拍摄距离等。
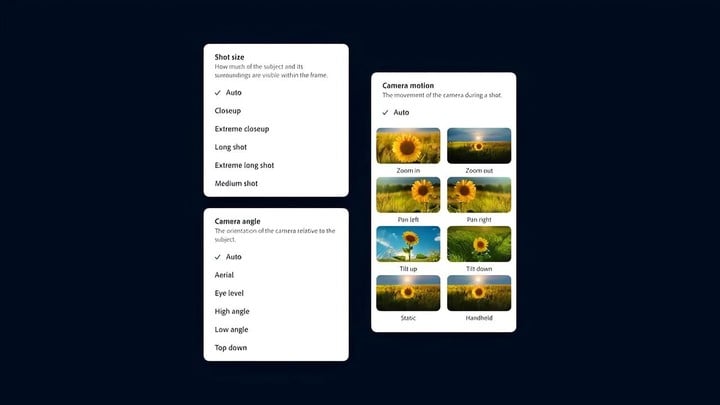
▲ 相机控制选项(图片来源:Adobe)
Image-to-Video功能则更进一步,允许用户在视频创作过程中添加「参考图像」,以生成更加贴近用户想象的视频。
视频创作者可以从一张图像和照片出发,利用Image-to-Video功能直接制作「B-roll」(电影和视频制作术语,指的是除了主要拍摄内容(A-roll)之外的辅助视频素材)。
用户还可以通过上传视频的单帧,并由Image-to-Video自动补充缺失帧,以此来创建完整的特写镜头。

▲提示文本:花朵在风中摇曳,一只美丽的蝴蝶落在其中一朵花上。(图片来源:Adobe)
「众所周知,视频不能P,所以一定是真的。」
然而,Image-to-Video的「赛博重拍」功能,直接让这句话变成过去式。它宛如一只「上帝之手」,可以让用户对视频内容(视频中的人物动作等)直接进行操作和修改。来看下面的例子:

▲ 原视频片段(图片来源:Adobe)

▲修改后的视频片段,提示文本:一只戴着手套的宇航员的手进入画面,并拔掉了其中一根黄色电缆,具有电影感。(图片来源:Adobe)
目前,Text-to-Video和Image-to-Video功能生成视频片段的最大长度仅为五秒钟,质量最高为720p和每秒24帧。视频生成时间大约为90秒,Adobe正在开发「涡轮模式」来缩短这一时间。
视频生成质量的不足表明,用户还无法用Firefly Video Model生成一部完整的电影,暂时只能作为创作辅助工具来使用。
Adobe强调,Firefly Video Model只会在许可内容(如Adobe Stock)和公共领域内容上对该模型进行训练,而不会在客户提供的内容上进行。
英文版:
Recently, the AI video field has been bustling, and Adobe has just joined this melee.
At this year's Adobe Max conference, Adobe officially launched its own AI video model - Firefly Video Model, entering the realm of generative artificial intelligence.
Adobe's Chief Product Marketing Manager Meagan Keane stated that the launch of Firefly Video Model aims to simplify and accelerate video creation, as well as enhance the storytelling capabilities of videos. In summary, this model includes three interesting and practical features:
- Generative Extend
- Text-to-Video
- Image-to-Video
Among them, Generative Extend has already been integrated into Adobe's professional video editing software Premiere Pro; Text-to-Video and Image-to-Video have just been released in beta version on the Firefly Web app.
As the name suggests, if your video clips are too short or missing certain parts, Generative Extend can help you "generatively extend" the beginning or end of the video clip.
In other words, if the required footage is not available, or if a clip's editing timing is too early or too late, the editor only needs to drag the beginning or end of the video clip, and Generative Extend can automatically fill in generative content to maintain the video's continuity and smoothness.
▲Demonstration of Generative Extend's generative video extension function (Image source: Adobe)
This means that if a video creator obtains a "useless shot" during the shooting process, they may no longer need to return to the original location for reshooting, but can use Generative Extend to directly extend and repair the original clip.
To a certain extent, this can indeed help improve video creation efficiency - of course, provided that the quality of the segments extended by Generative Extend is solid.
Unfortunately, the current maximum resolution limit of this function is 1080p, and the maximum expansion of a segment is only two seconds.
Therefore, Generative Extend is only suitable for making minor adjustments to video clips, meaning it can help users fix certain details, but cannot replace the creators themselves for extensive creation.
Generative Extend can also help users make adjustments during the shooting process, correcting eye shifts or other unexpected movements that occur during shooting.
Aside from videos, Generative Extend can also be used for smooth editing of audio. It can extend environmental background sound effects in a video for up to ten seconds, but cannot extend dialogues or music.
▲Representation of Generative Extend's audio extension function (Image source: Adobe)
If you want to save some effort in the video creation process, you can directly generate videos using the Text-to-Video feature. Like its "predecessors" Runway and OpenAI's Sora, users only need to input text descriptions of the videos they want to generate, and the function can simulate various styles such as "real film," "3D animation," and "stop-motion animation" to create corresponding video clips.
Here are some video clips generated using the Text-to-Video feature for you to experience:
▲Prompt text: A movie drone flies over the vast red Mars landscape. It zooms past us from below, and as the sun rises, the horizon is red. At the end of the shot, the sun rises from the horizon. (Image source: Adobe)
▲Prompt text: Close-up of an elderly man in the middle of a night street. The lighting atmosphere is gloomy and dramatic. The color grading is blue shadows and orange highlights. This man has extremely realistic details of skin texture and distinct pores. The movements are subtle and soft. The camera is still. Film grain. Old-fashioned distorted lens. (Image source: Adobe)
▲Prompt text: A view shot inside a beautiful, soft courtyard in Mexico. The water is clear and deep blue, sparkling in the evening sun. The colors are warm and magical fantasy style. High quality, cinematic feel. (Image source: Adobe)
In addition to realistic, cinematic visual images, Text-to-Video also supports generating some "abstract" scenes. For example, it can be used to generate videos with elements like flames, water, lens flares, and smoke, which can be overlaid on existing videos to enhance the visual depth and interest of the content.
▲Prompt text: Cinematic lens flares on a black background, organic feel, realistic. (Image source: Adobe)
▲Video segment synthesized with the existing video after composition (Image source: Adobe)
It is worth mentioning that the video clips generated using Text-to-Video can also be further refined using a series of "camera controls" that can simulate real camera angles, movement, and shooting distances.
▲ Camera control options (Image source: Adobe)
The Image-to-Video function goes even further, allowing users to add "reference images" in the video creation process to generate videos that are closer to what the user imagines.
Video creators can start from a single image or photo and use the Image-to-Video function to directly produce "B-roll" (a filmmaking term for supplementary video footage other than the main footage) videos.
Users can also upload a single frame of a video and let Image-to-Video automatically fill in missing frames to create complete close-up shots.
▲Prompt text: Flowers swaying in the wind, a beautiful butterfly landing on one of the flowers. (Image source: Adobe)
"It is well known that videos cannot be Photoshopped, so they must be real."
However, the "cyber reshoot" function of Image-to-Video makes this statement a thing of the past. It acts like a "God's hand" that allows users to directly manipulate and modify video content (such as character actions in the video). Take a look at the examples below:
▲ Original video segment (Image source: Adobe)
▲ Modified video segment, prompt text: A gloved astronaut's hand enters the frame and unplugs one of the yellow cables, giving a cinematic feel. (Image source: Adobe)
Currently, the maximum length of the video clips generated by the Text-to-Video and Image-to-Video functions is only five seconds, with the highest quality being 720p and 24 frames per second. The video generation time is approximately 90 seconds, and Adobe is developing a "turbo mode" to shorten this time.
The insufficient quality of the generated videos indicates that users still cannot use the Firefly Video Model to generate a complete film, and can only use it as an auxiliary tool for creation.
Adobe emphasizes that the Firefly Video Model is only trained on licensed content (such as Adobe Stock) and public domain content, and will not be used on customer-provided content.
In addition, videos created or edited using the Firefly Video Model can embed content credentials, intended to provide attribution proof for creators and content sources, helping to declare AI usage and ownership rights to ensure "business security."
Interested readers can join the Adobe Firefly Video Model experience waitlist at the following link:
https://www.adobe.com/products/firefly/features/ai-video-generator.html
叫板 Sora! Adobe 推出 AI 视频神器,一句话 P 视频
#叫板 #Sora #Adobe #推出 #视频神器一句话 #视频
关注流程:打开随信App→搜索擒数网随信号:973641 →订阅即可!
公众号:擒数网 抖音:擒数网
视频号:擒数网 快手:擒数网
小红书:擒数网 随信:擒数网
百家号:擒数网 B站:擒数网
知乎:擒数网 微博:擒数网
UC头条:擒数网 搜狐号:擒数网
趣头条:擒数网 虎嗅:擒数网
腾讯新闻:擒数网 网易号:擒数网
36氪:擒数网 钛媒体:擒数网
今日头条:擒数网 西瓜视频:擒数网




